Image Captioning
A project in which I implemented a Neural Image Caption (NIC) network to generate image captions
Motivation
Automatically describing the content of an image, or “Image Captioning,” is a major task in computer vision and natural language processing. It involves generating a textual description that reflects the content of a given image. As part of my second year of Master’s degree, I developed a project where I implemented a NIC (Neural Image Captioning) neural network, leveraging the model proposed in the influential “Show and Tell” paper proposed by Vinyals, Oriol et al.
Neural Image Caption (NIC)
The NIC model is a deep neural network, based on machine translation models, that utilizes an encoder-decoder architecture. The encoder is a convolutional neural network (CNN) that transforms the image into a vector representation. The decoder, a recurrent neural network (RNN), uses this representation to generate a sequence of words describing the image.
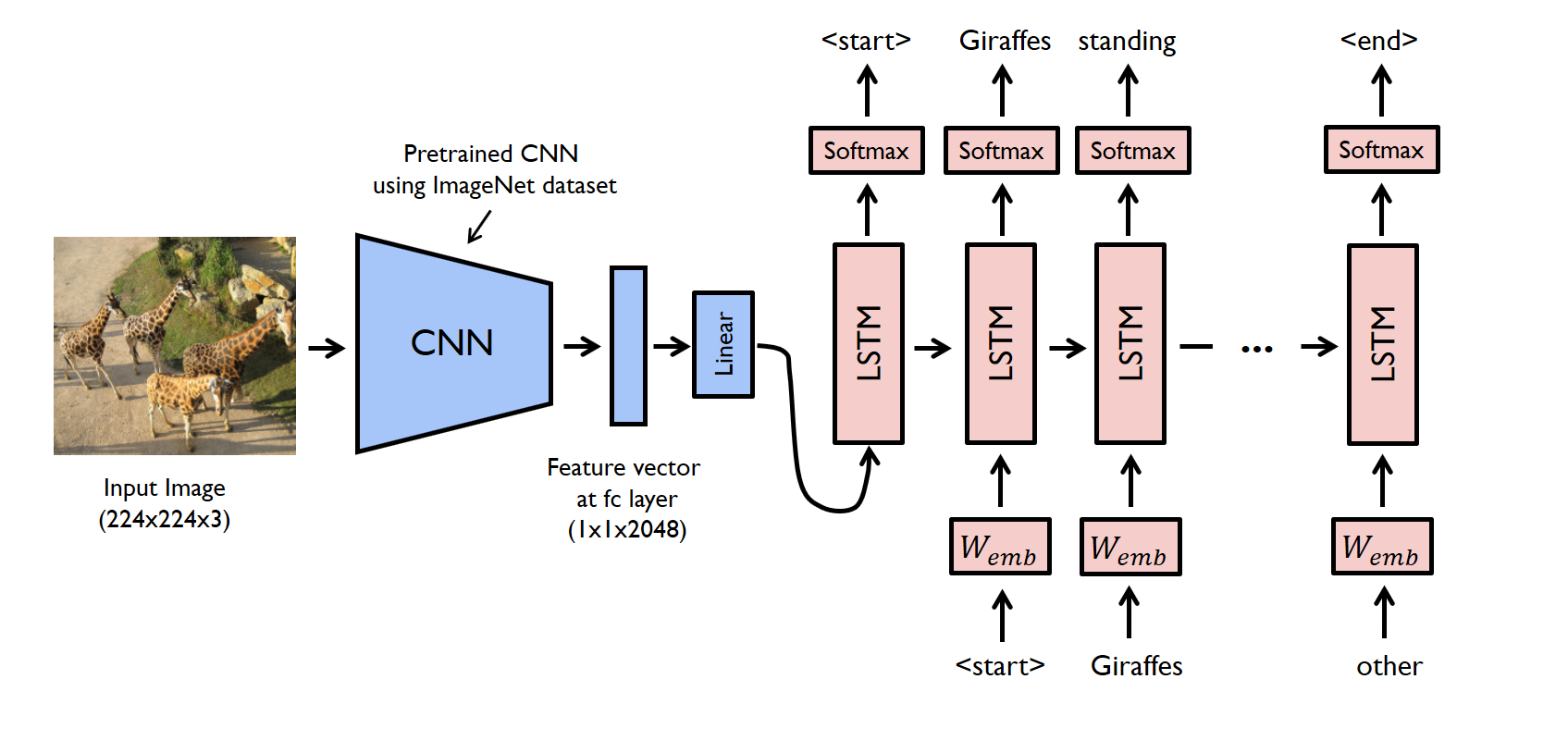
Implementation
Dataset
The dataset used in this project is Flickr8k, a collection of 8000 images, each associated with five different captions from six different Flickr groups. The images have been manually selected to represent a variety of scenes and situations.
Illustration of images from the dataset along with their associated captions:

CNN Encoder
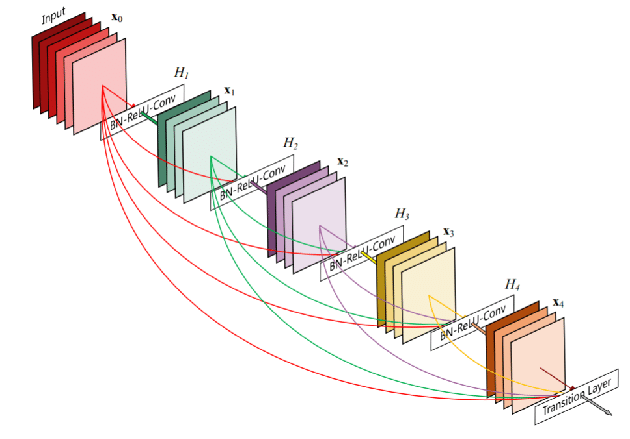
The architecture presented in the article is independent of the choice of CNN. Here, I used DenseNet201 loaded with the ImageNet weights to extract image features upstream, with the goal of reducing the training burden.
Illustration of a DenseBlock, a key element of DenseNet:
RNN Decoder
Here, the decoder used is a Long Short-Term Memory (LSTM). Its role is to decode the feature vector obtained from the CNN into a caption. It is trained to predict each word of the caption after seeing the image and all the previous words.
Illustration of the final network obtained:

Inference
Many different methods can be used to decode the caption generated by NIC:
- Sampling: This method generates the next word by randomly sampling from the probability distribution of the words predicted by the model. This can lead to more diverse results, but sometimes less coherent.
- Beam Search: This method keeps the top
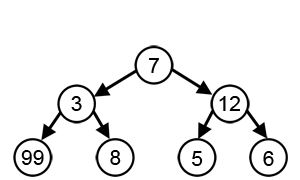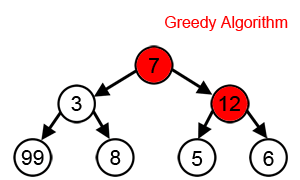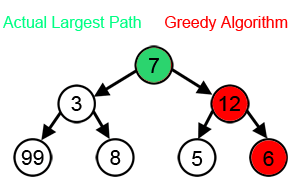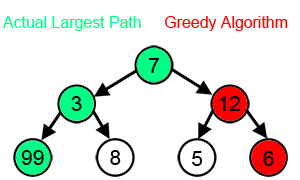
kcaptions at each prediction step. With each new word, it expands thesekcaptions and retains only the topkamong them. This allows for more accurate results than sampling or greedy search, but is more computationally expensive. - Greedy Search: This method always chooses the word with the highest probability as the next word in the caption. It is the fastest and simplest approach but can sometimes result in suboptimal results as it does not consider probabilities of subsequent words. Greedy search can be seen as a special case of beam search with
k = 1.
Here, I chose to use Greedy Search as it is a good compromise between performance and implementation time.
Illustration of Greedy Search:
Evaluation
Examples
Before diving into the metrics, here are a few examples of captions generated by NIC.

Metrics
Before presenting the results, it is important to understand the different metrics used to evaluate the quality of the generated captions:
-
BLEU (Bilingual Evaluation Understudy) 1 to 4:
- Measures the correspondence between the generated sentences and the reference sentences.
- Considers the accuracy of n-grams
N-grams are groups of "n" consecutive words in a text. For example, in "I love science", a 2-gram (or bigram) would be ["I love", "love science"]. (from 1 to 4 words).
-
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
- Measures the model’s ability to include key words.
- Focuses on the recall of n-grams.
-
METEOR (Metric for Evaluation of Translation with Explicit ORdering):
- Compares the generated text with the references, taking into account synonymy, morphological variations, and word order.
- Aims to improve correlation with human evaluation.
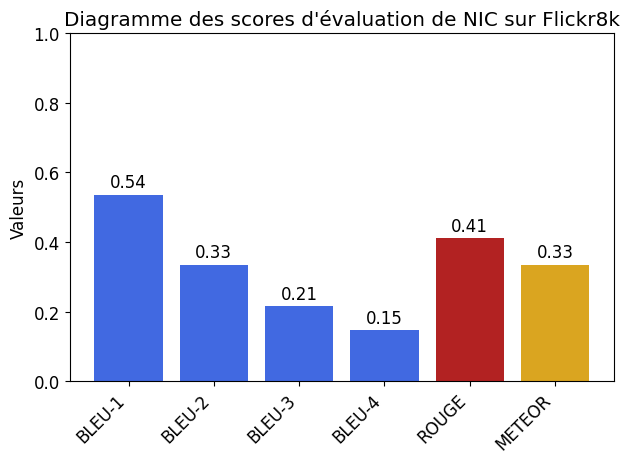
Scores
The obtained scores are correct, and it can be observed that the model makes sense of most of the images. For reference, human BLEU and ROUGE scores are approximately around 70%, so higher scores would be unlikely.
Comparison
Here are the results from an implementation conducted by Arthur Benard, who utilized the encoder portion of CLIP
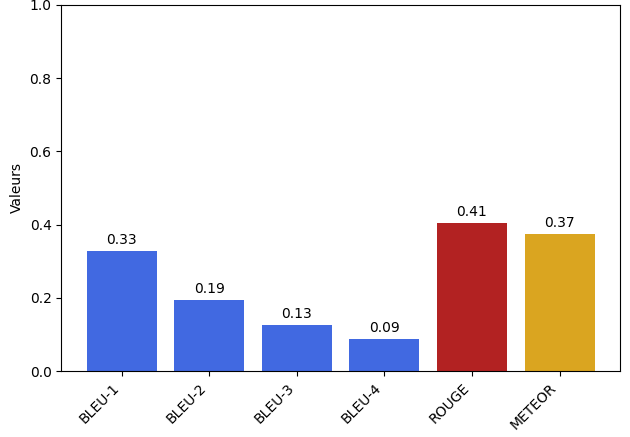
We can notice that the results are slightly different, with lower BLEU scores, equivalent ROUGE scores, and higher METEOR scores. This could indicate that the generated captions may have a different structure but keep a meaning closer to what a human would describe.
Conclusion
In this project, I was able to implement one of the foundation models in the field of image captioning, achieving correct results. The model appears to have a relative understanding of the images, while having some recurring issues such as counting people or animals, overusing “in a blue shirt” for other clothing colors, etc.
In the future, it would be interesting to explore certain points to improve the model:
- Changing the architecture to incorporate attention mechanisms, as in “Show, Attend and Tell” by Xu, Ke et al.
- Using a larger training dataset such as Flickr30k
or MS COCO - Employing an encoder and/or decoder pre-trained on a larger corpus
- Using Beam search with
k > 1for inference